
项目分析:
给定数据集为 某外卖平台收集的用户评价,正向评价4000条,负向评价8000条,根据词语级情感倾向性分析的内容,采用选定种子词的方式找出最具有正向/负向情感倾向的50个词语。
本实验通过两种工具完成了两种实现方式。项目前期工作都相同,到情感分析部分可以通过两种方式实现。
Outline:
- 项目分析
- 项目实现
- 实验结果
此处需用到的包(Reference):
- 将
句子切分成若干词语- https://github.com/fxsjy/jieba jieba 中文分词工具
- 文本情感分析工具
- https://github.com/thunlp/OpenHowNet HowNet(大型中文语言知识库)OpenHowNet-基于词典的词语情感分析工具
- https://github.com/isnowfy/snownlp Snownlp - 中文处理工具
项目实现
Step1 处理数据集
数据集为csv文件,长这样:
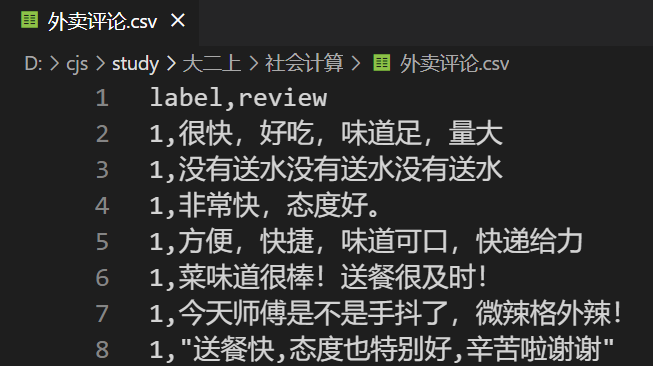
当我们用csv.reader读取每一行时,每一行的第一个元素0、1代表target,数据从第三个元素开始。
此处用target对读取数据进行分类,同时为了后续处理方便,将每一行的列表转化为字符串类型再分别读入pos_comments和neg_comments两个列表中
数据处理部分代码如下:
def read_file(filename, pos_comments, neg_comments):
with open(filename, encoding='UTF-8') as f:
reader = csv.reader(f)
for row in reader:
target = row[0]
# row 此时是 列表 ['俩小时。,我醉啦!'],['咸死我啦……']
row = ''.join(row)
# 转换成了string '送餐很快,味道一般', '包装超级好、味道也不错'
if(target == '1'):
pos_comments.append(row[1:])
elif(target == '0'):
neg_comments.append(row[1:])
Step2 分词
此处实现分词的核心工具是使用jieba,查阅官方文档得,可得到分词的具体使用方式,此处使用jieba.cut()
jieba.cut方法接受四个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型;use_paddle 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
将正向评论的分词加入到pos_words中,负向加入到neg_words中,为了方便查看并选取种子词,将其分别写入.csv文件。
但发现效果并不好,出现大量标点符号和重复词语。

故使用purify对words进行处理。分别是 删除经常出现的标点、删除单音节词(单音节词会对后面情感分析造成影响)、去重(此处只分析情感倾向,与出现频率没有关系,所以要去重)。
删除常用的标点需要用while循环进行删除,remove只是发现并删除一个。
purify之后的分词就纯多了:

代码如下:
def delete_single_words(words): # 删除单音节词
i = 0
while i < len(words):
if len(words[i]) == 1:
words.pop(i)
else:
i += 1
def purify(words): # 删除标点、去除单音节词和去重
punc = [",", "。", "!", "~", "~", "!", "'", ".", "?", "、", "…"] # 删除被当做词的标点
for item in punc:
while item in words:
words.remove(item)
delete_single_words(words) # 删除单音节词
words = list(set(words)) # 去重
return words
def cut_words(pos_comments, neg_comments, pos_words, neg_words):
# jieba.enable_paddle()
for comment in pos_comments:
pos_words += jieba.cut(comment) # 此处可选 精确模式 or 全模式
for comment in neg_comments:
neg_words += jieba.cut(comment)
# pos_words ['很快', ',', '好吃', ','] 都是列表
# neg_words ['菜品', '质量', '好', ',', '味道']
pos_words = purify(pos_words)
neg_words = purify(neg_words)
with open("positive_words.csv", 'w', encoding="UTF-8", newline='') as f1:
writer = csv.writer(f1)
writer.writerow(pos_words)
with open("negetive_words.csv", 'w', encoding="UTF-8", newline='') as f2:
writer = csv.writer(f2)
writer.writerow(neg_words)
Step3 选取种子词
此处比较具有主观能动性,种子词的选取要正负情感倾向比较强,比较典型的词语
此处选取种子词为
pos_seedset = (['好吃', '满意', '可口', '美味', '满足', '足够', '香甜', '爱上'])
neg_seedset = (['失误', '差劲', '失望', '错误', '肮脏', '气人', '不满', '慢'])
Step4 情感分析
情感分析部分可以采用两种实现方式,分别是使用HowNet的api接口,以及中文的语言处理工具snownlp,后者的情感分析也是通过基于词典的方式实现的。
HowNet实现
此处使用清华大学的一个开源库,OpenHowNet
使用此库需先
pip install OpenHowNet
之后在代码前面先引用
import OpenHowNet
此处用到的函数为 calculate_word_similarity(self, word0, word1) ,作用是计算两个词的相似度。
数值越大则说明两个词越相似, 如“好吃”和“美味”的输出就是1,”苹果“和”梨“的输出也是1,而”好吃“和”还行“的输出则是-1.


分析之前,先建立词典并初始化hownet:
hownet_dict = OpenHowNet.HowNetDict()
hownet_dict.initialize_sememe_similarity_calculation()
zh_dict = hownet_dict.get_zh_words()
之后用到的情感倾向分析的方法是 用 num_polar 量化情感倾向,将每一个词分别与正向种子词、负向种子词通过上述函数计算相似度,并将与正向种子词的相似度加上,将负向种子词的相似度减去,以得到的 num_polar 为情感倾向指数进行排序,数值越大则越正向,数值越小越负向。
用HowNet做情感分析代码如下:
def emo_analyse(words, pos_seedsets, neg_seedsets):
# OpenHowNet.download() # 第一次运行需下载HowNet的core data
hownet_dict = OpenHowNet.HowNetDict(init_sim=True)
hownet_dict.initialize_sememe_similarity_calculation()
for i in range(len(words)):
# 打印进度条
sys.stdout.write('\r')
sys.stdout.write(
"%s%% |%s" % (int((i + 1) * 100 / len(words)), int((i + 1) * 100 / len(words)) * '#'))
sys.stdout.flush()
# time.sleep(0.001)
word = words[i]
num_polar = 0
num_polar_0 = 0
num_polar_1 = 0
if word not in zh_dict:
words[i] = (word, num_polar)
continue
for p in pos_seedset:
num_polar_0 += hownet_dict.calculate_word_similarity(word, p)
num_polar_0 = num_polar_0 / len(pos_seedset) # 得正向的平均值
for q in neg_seedset:
num_polar_1 -= hownet_dict.calculate_word_similarity(word, q)
num_polar_1 = num_polar_1 / len(neg_seedset) # 得负向的平均值
num_polar = num_polar_0 + num_polar_1
words[i] = (word, num_polar)
snownlp实现
此处用到自然语言处理工具snownlp,优点是功能较多且轻便好用。
使用前先
from snownlp import SnowNLP as snlp
其功能较多,此处用到其中两个,分别是:
情感分析
.sentimentsSnowNLP的情感分析是基于自带的两个积极跟消极的语料文件来进行分析的(neg.txt、pos.txt)。这两个语料文件是某平台的评论留言,主要有关于书本的、酒店的、电脑及配件的几个方向的评价留言。情感分析的结果是一个小数,越接近1,说明越偏向积极;越接近0,说明越偏向消极。
e.g.
>>> text1 = '这是我遇见的最棒的一家店,种类多,价格低,更喜欢的是服务质量很好' >>> print(s1.sentiments) 0.99509716108733相似度分析
.sim为0-1的数,越大则说明越相似,越小则越不相似。
e.g.
>>> s = SnowNLP(['深度学习', '自然语言处理']) >>> artilc1 = ['自然语言处理'] >>> print(s.sim(artilc1)) [0.4686473612532025]
发现这两个函数都与情感倾向分析有关,所以可以用不同的运算关系表征最后的情感倾向。这里将而且根据一定权重相加,即
num_polar = 情感分析得到输出 / 2 + 相似度
而对相似度的分析,与上面HowNet的处理方式同。
运用snownlp进行情感分析的代码如图(与上面相比多了情感得分一项,大致思路同):
def emo_analyse(words, pos_seedset, neg_seedset):
# OpenHowNet.download() # 第一次运行需下载HowNet的core data
for i in range(len(words)):
# 打印进度条
sys.stdout.write('\r')
sys.stdout.write(
"%s%% |%s" % (int((i + 1) * 100 / len(words)), int((i + 1) * 100 / len(words)) * '#'))
sys.stdout.flush()
time.sleep(0.001)
word = words[i]
num_polar = 0
emo_trend = snlp(words[i]).sentiments # 正/负项情感得分
sim = pos_seedset.sim(word) # 相似度
sum = 0
for j in range(len(sim)):
sum += sim[j]
sim = neg_seedset.sim(word)
for j in range(len(sim)):
sum -= sim[j]
num_polar = sum + emo_trend / 3
words[i] = (word, num_polar) # 改变words元素的性质
Step5 结果处理
由上面的分析过程,words已经改变为二元元组,所以对其第二项进行排序,需用到lambda ,之后将结果保存到xlsx文件中。
pos_words.sort(key=lambda x: int(x[1]), reverse=True) # 使用降序排列
neg_words.sort(key=lambda x: int(x[1]), reverse=False) # 升序排序
print("")
print("most positive:")
print(pos_words[:50])
print("\nmost negtive:")
print(neg_words[:50])
# 以表格的形式保存答案
pos = pandas.DataFrame(pos_words)
neg = pandas.DataFrame(neg_words)
pos.to_excel("most_positive_words.xlsx")
neg.to_excel("most_negative_words.xlsx")
实验结果
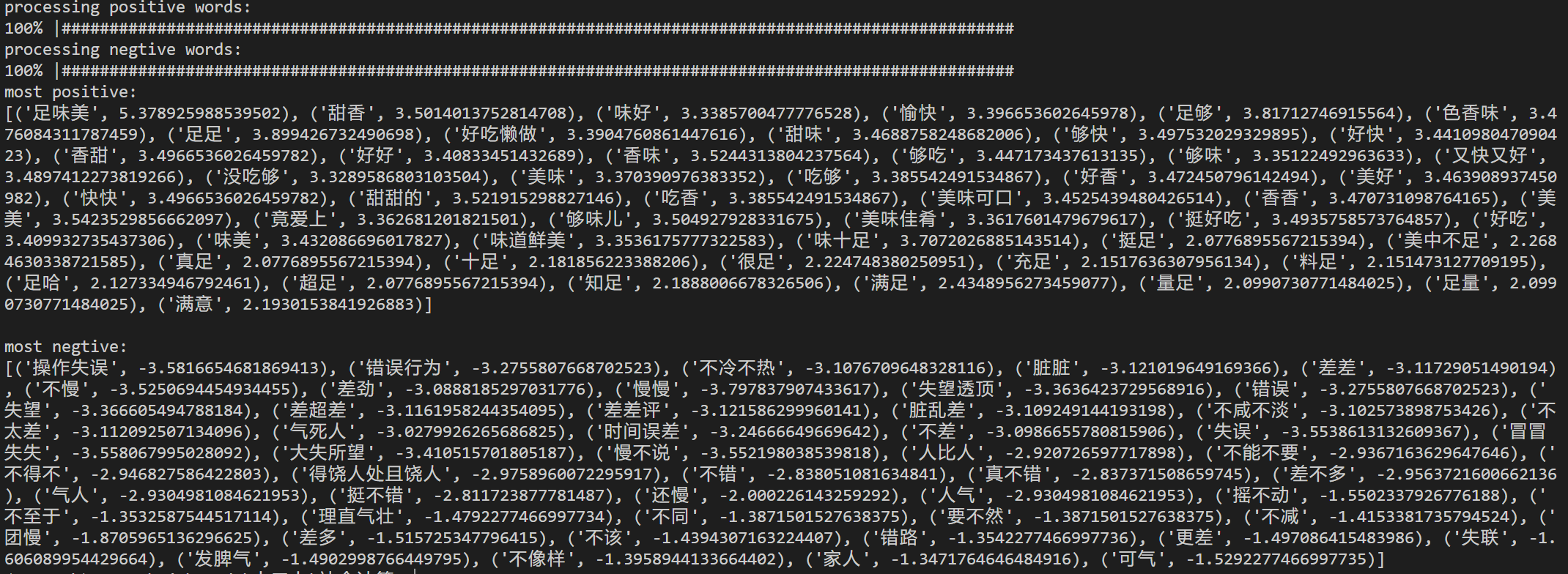
使用sort()函数进行排序后发现有些误差,猜测可能是因为Python的sort函数排序精度的问题?
最终得到结果:
| most positive | num_polar | most negative | num_polar | |||
|---|---|---|---|---|---|---|
| 0 | 足味美 | 5.378925989 | 0 | 操作失误 | -3.581665468 | |
| 1 | 甜香 | 3.501401375 | 1 | 错误行为 | -3.275580767 | |
| 2 | 味好 | 3.338570048 | 2 | 不冷不热 | -3.107670965 | |
| 3 | 愉快 | 3.396653603 | 3 | 脏脏 | -3.121019649 | |
| 4 | 足够 | 3.817127469 | 4 | 差差 | -3.117290515 | |
| 5 | 色香味 | 3.476084312 | 5 | 不慢 | -3.525069445 | |
| 6 | 足足 | 3.899426732 | 6 | 差劲 | -3.08881853 | |
| 7 | 好吃懒做 | 3.390476086 | 7 | 慢慢 | -3.797837907 | |
| 8 | 甜味 | 3.468875825 | 8 | 失望透顶 | -3.363642373 | |
| 9 | 够快 | 3.497532029 | 9 | 错误 | -3.275580767 | |
| 10 | 好快 | 3.441098047 | 10 | 失望 | -3.366605495 | |
| 11 | 香甜 | 3.496653603 | 11 | 差超差 | -3.116195824 | |
| 12 | 好好 | 3.408334514 | 12 | 差差评 | -3.1215863 | |
| 13 | 香味 | 3.52443138 | 13 | 脏乱差 | -3.109249144 | |
| 14 | 够吃 | 3.447173438 | 14 | 不咸不淡 | -3.102573899 | |
| 15 | 够味 | 3.35122493 | 15 | 不太差 | -3.112092507 | |
| 16 | 又快又好 | 3.489741227 | 16 | 气死人 | -3.027992627 | |
| 17 | 没吃够 | 3.32895868 | 17 | 时间误差 | -3.246666497 | |
| 18 | 美味 | 3.370390976 | 18 | 不差 | -3.098665578 | |
| 19 | 吃够 | 3.385542492 | 19 | 失误 | -3.553861313 | |
| 20 | 好香 | 3.472450796 | 20 | 冒冒失失 | -3.558067995 | |
| 21 | 美好 | 3.463908937 | 21 | 大失所望 | -3.410515702 | |
| 22 | 快快 | 3.496653603 | 22 | 慢不说 | -3.552198039 | |
| 23 | 甜甜的 | 3.521915299 | 23 | 人比人 | -2.920726598 | |
| 24 | 吃香 | 3.385542492 | 24 | 不能不要 | -2.936716363 | |
| 25 | 美味可口 | 3.452543948 | 25 | 不得不 | -2.946827586 | |
| 26 | 香香 | 3.470731099 | 26 | 得饶人处且饶人 | -2.975896007 | |
| 27 | 美美 | 3.542352986 | 27 | 不错 | -2.838051082 | |
| 28 | 竟爱上 | 3.362681202 | 28 | 真不错 | -2.837371509 | |
| 29 | 够味儿 | 3.504927928 | 29 | 差不多 | -2.95637216 | |
| 30 | 美味佳肴 | 3.361760148 | 30 | 气人 | -2.930498108 | |
| 31 | 挺好吃 | 3.493575857 | 31 | 挺不错 | -2.811723878 | |
| 32 | 好吃 | 3.409932735 | 32 | 还慢 | -2.000226143 | |
| 33 | 味美 | 3.432086696 | 33 | 人气 | -2.930498108 | |
| 34 | 味道鲜美 | 3.353617578 | 34 | 摇不动 | -1.550233793 | |
| 35 | 味十足 | 3.707202689 | 35 | 不至于 | -1.353258754 | |
| 36 | 挺足 | 2.077689557 | 36 | 理直气壮 | -1.479227747 | |
| 37 | 美中不足 | 2.268463034 | 37 | 不同 | -1.387150153 | |
| 38 | 真足 | 2.077689557 | 38 | 要不然 | -1.387150153 | |
| 39 | 十足 | 2.181856223 | 39 | 不减 | -1.415338174 | |
| 40 | 很足 | 2.22474838 | 40 | 团慢 | -1.870596514 | |
| 41 | 充足 | 2.151763631 | 41 | 差多 | -1.515725348 | |
| 42 | 料足 | 2.151473128 | 42 | 不该 | -1.439430716 | |
| 43 | 足哈 | 2.127334947 | 43 | 错路 | -1.354227747 | |
| 44 | 超足 | 2.077689557 | 44 | 更差 | -1.497086415 | |
| 45 | 知足 | 2.188800668 | 45 | 失联 | -1.606089954 | |
| 46 | 满足 | 2.434895627 | 46 | 发脾气 | -1.490299877 | |
| 47 | 量足 | 2.099073077 | 47 | 不像样 | -1.395894413 | |
| 48 | 足量 | 2.099073077 | 48 | 家人 | -1.347176465 | |
| 49 | 满意 | 2.193015384 | 49 | 可气 | -1.529227747 |
对表格中的各关键词进行可视化后,得到如下结果:
正向:
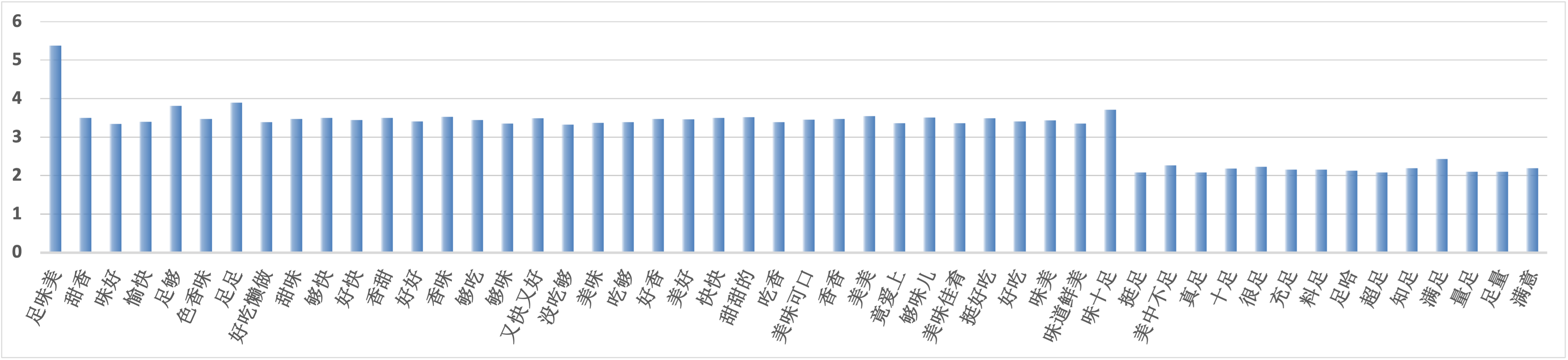
负向:
